

Introduction to 3D Object Detection Using Deep Learning From Lidar Point Clouds
Introduction
In this blog post, we will briefly review what the LIDAR sensor is, how it works, the data shape and format of LIDAR point clouds, the techniques used in 3d-Object detection that are originally tailored from 2d-object detection networks. While the mostly used dataset is the older KITTI, we will review one of the newer and richer benchmarking dataset for this task (Pandaset).
What Is A Lidar Sensor?
Lidar (light detection and ranging) is a method for measuring distances by sending a laser pulse to a target or a scene and measuring the reflections with a sensor. Lidar sensors are used to create point clouds. A point cloud is a concatenation of all points captured during a single sweep of the LIDAR sensor. It represents a 3D shape or feature. Each point has its own set of X, Y and Z coordinates and in some cases additional attributes like the intensity of the reflection.
How Does It Work?
Active sensors with their own laser illumination source are used in LIDAR. The energy source strikes the surfaces, and sensors detect and measure the reflected energy. Distance to the object is determined by recording the time between transmitted and received (reflected) pulses and by using the speed of light to calculate the distance traveled.
- The GIF roughly demonstrates how LiDAR works. Basically, laser beams are shot in all directions by a laser with a specific step or resolution that differs from one LIDAR to another. The laser beams reflect off the objects in their path and the reflected beams are collected by a sensor. 3D maps are created using the information from these sensor
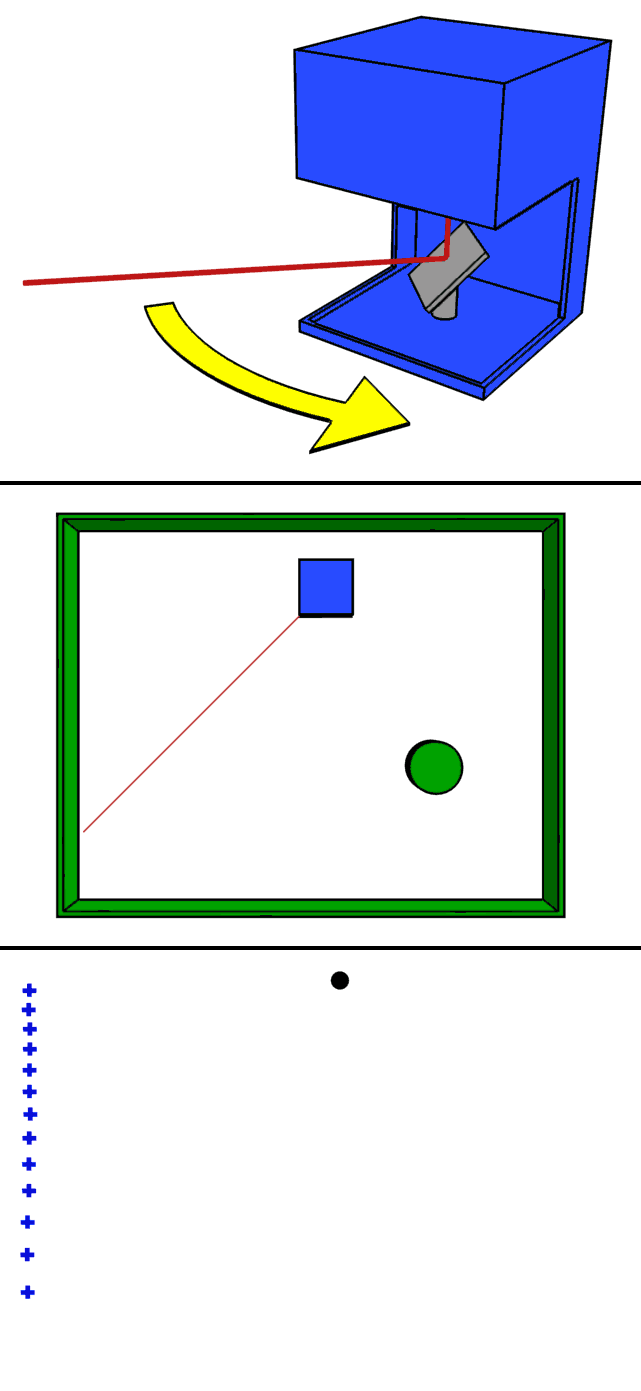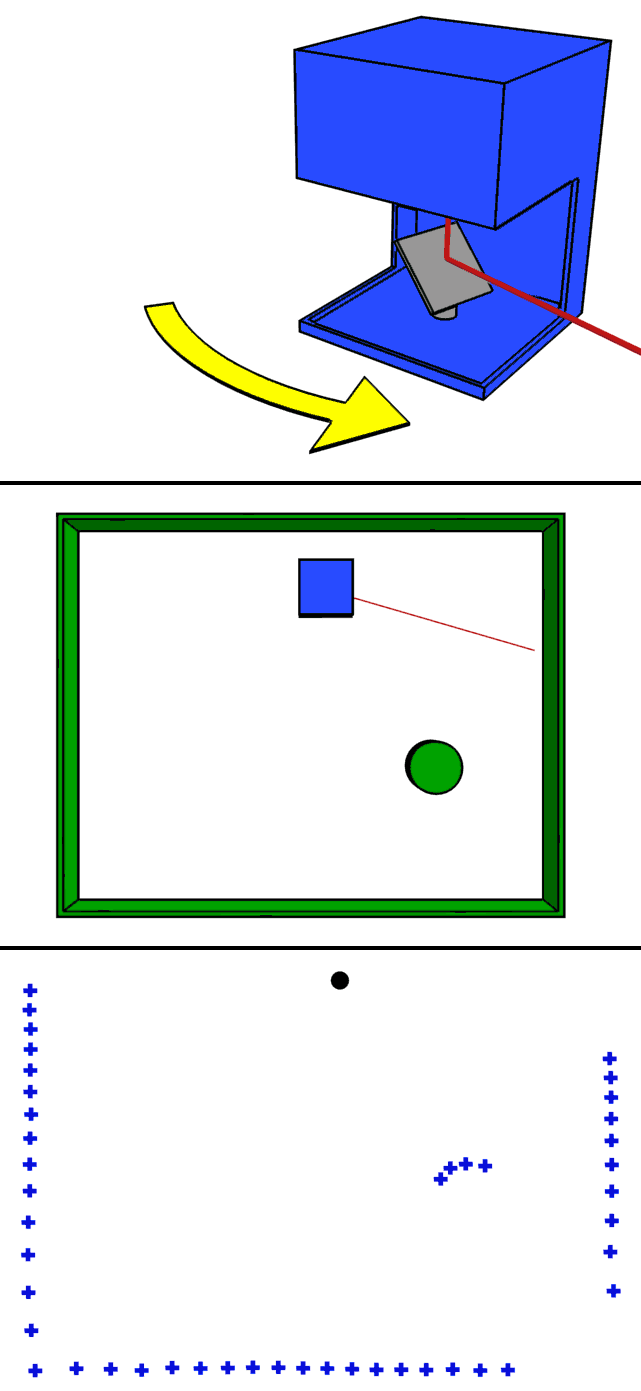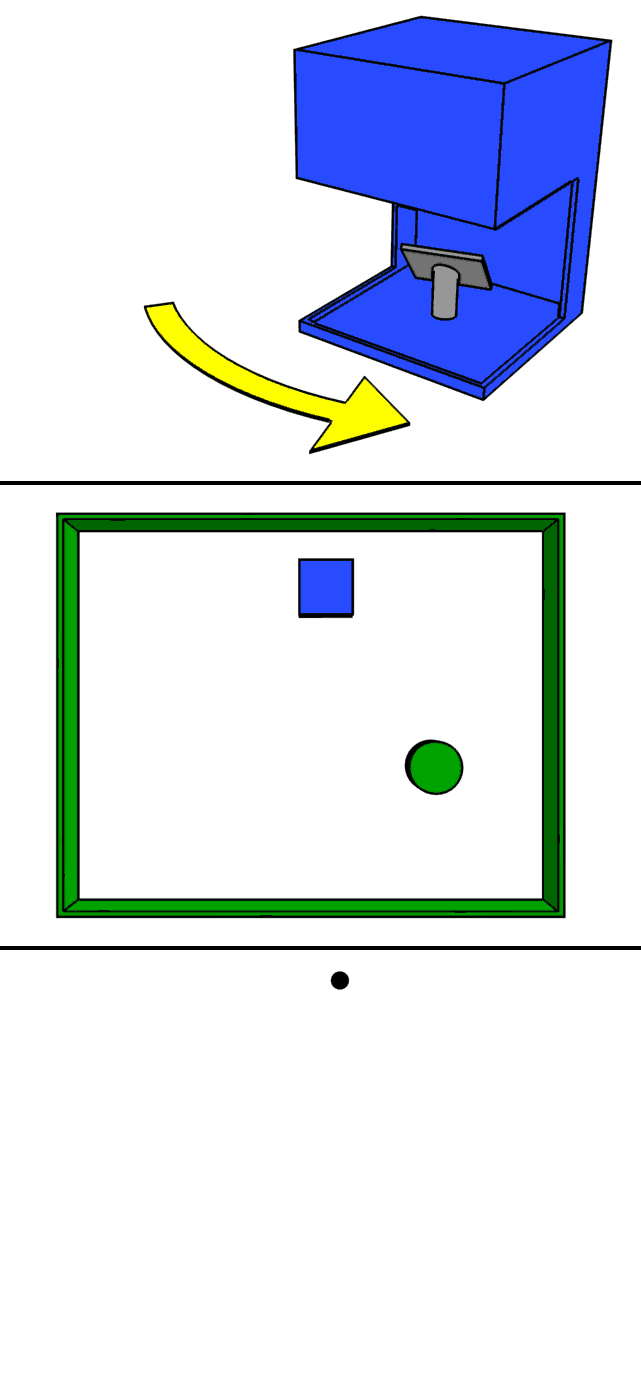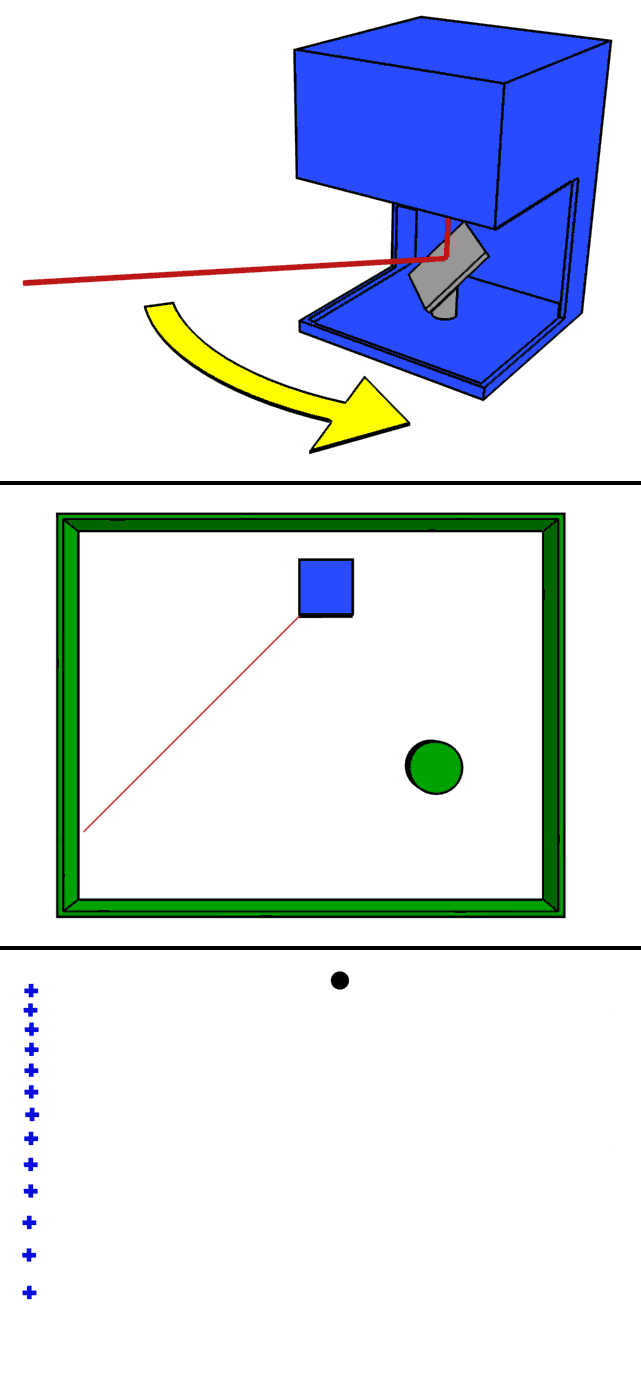
Features Collected
Data consists of rows and columns of pixels with ample "depth" and "intensity" to create 3D landscape models. Each pixel records the time it takes each laser pulse to reach the target and return to the sensor, as well as the depth, position, and reflective intensity of the object that the laser pulse is contacting. When all those data points are collected, they are called a point cloud and they appear as the below image. The yellow boxes represent vehicles bounding boxes.

Applications
LIDAR is used in many applications, mainly in autonomous driving cars to detect objects in order to navigate safely through environments. LIDAR is widely used in video games to reproduce environments from 3D point clouds, resulting in very accurate replicated environments, like replicating a whole town inside a video game. It is also used in Agriculture, Archaeology, Mining and many more.
Data Shape And Extensions
The data is usually in 3 dimensions, representing x, y and z of the reflected laser beams.
Additional dimensions could also be present, representing the intensity of reflected light which could help in identifying specific materials and points clustering for single objects.
3D object detection methods
There are two types of 3D object detection methods: region proposal based and single shot methods. The region proposal bases methods work by proposing several possible regions containing objects, and then extract per region features. These features are then used to attempt object detection. These methods could be divided into:
- Multi-view based: Used multiple data sources like LiDAR front view, Bird’s Eye View (BEV), and camera images.
- Segmentation-based: uses semantic segmentation techniques to remove most background points, and then generate an amount of high-quality proposals on foreground points.
- frustum-based methods: uses existing 2D object detectors to generate 2D candidate regions of objects and then extract a 3D frustum proposal for each 2D candidate region.
Single shot methods directly predict class probabilities and regress 3D bounding boxes of objects using a single-stage network. They do not require region proposal generation and post-processing. They generally run at higher speed than Region proposals methods. These methods could be divided into:
- BEV-based Methods: These methods mainly take bird-eye view representation as their input. The point cloud is used to create a 2D image representation as if taken from a bird’s view. Normal 2D convolutional layers are then used to attempt object detection.
- Discretization-based Methods: These methods transform a point cloud into a standard discrete representation, then use CNN to predict object categories and 3D boxes. Basically the point cloud is transformed into a set of features that are then fed into a CNN network to attempt object detection.
- Point-based Method: These methods take raw point clouds as inputs directly.
Dataset: Pandaset
This dataset is released by SCALE AI and Hesai The dataset contains 48,000+ camera images, 16,000+ LiDAR sweeps with ~175,000 point per point cloud, 104 scenes of 8s each, 3D bounding boxes for 28 object classes and a rich set of per object attributes related to activity, visibility, pose and location. The sensor suite used during collection were 1x mechanical spinning LiDAR, 1x forward-facing LiDAR, 6x cameras and On-board GPS/IMU.

Panar64: 64-Channel Mechanical LiDAR

PandarGT: Solid-State LiDAR

References
Y. Guo, H. Wang, Q. Hu, H. Liu, L. Liu and M. Bennamoun, "Deep Learning for 3D Point Clouds: A Survey," in IEEE Transactions on Pattern Analysis and Machine Intelligence, doi: 10.1109/TPAMI.2020.3005434.
PandaSet by Hesai and Scale AI (https://pandaset.org/)











